By The Quick
Home
Friction Log: ClickHouse Kafka Connector

tl;dr
🌟 ClickHouse Cloud provides a built-in SQL console that is incredibly helpful for getting started and makes it easy to validate the connector is working.
😕 Couple of rough edges around the quickstart workflow and documentation.
Table of contents
Overview
The blog post Announcing a new official ClickHouse Kafka Connector was timely because I had wanted to learn more about databases specialized for analytics, and ClickHouse has a reputation for being a highly performant online analytical processing (OLAP) database.
I have prior experience with Apache Kafka®, but none with ClickHouse, so this seemed like a good opportunity to write a friction log (what's that?) on the developer experience with ClickHouse and the new Kafka connector.
Signup
A developer most likely starts with a Google search, and if the page has good SEO, it helps discoverability.
I search for clickhouse quickstart.
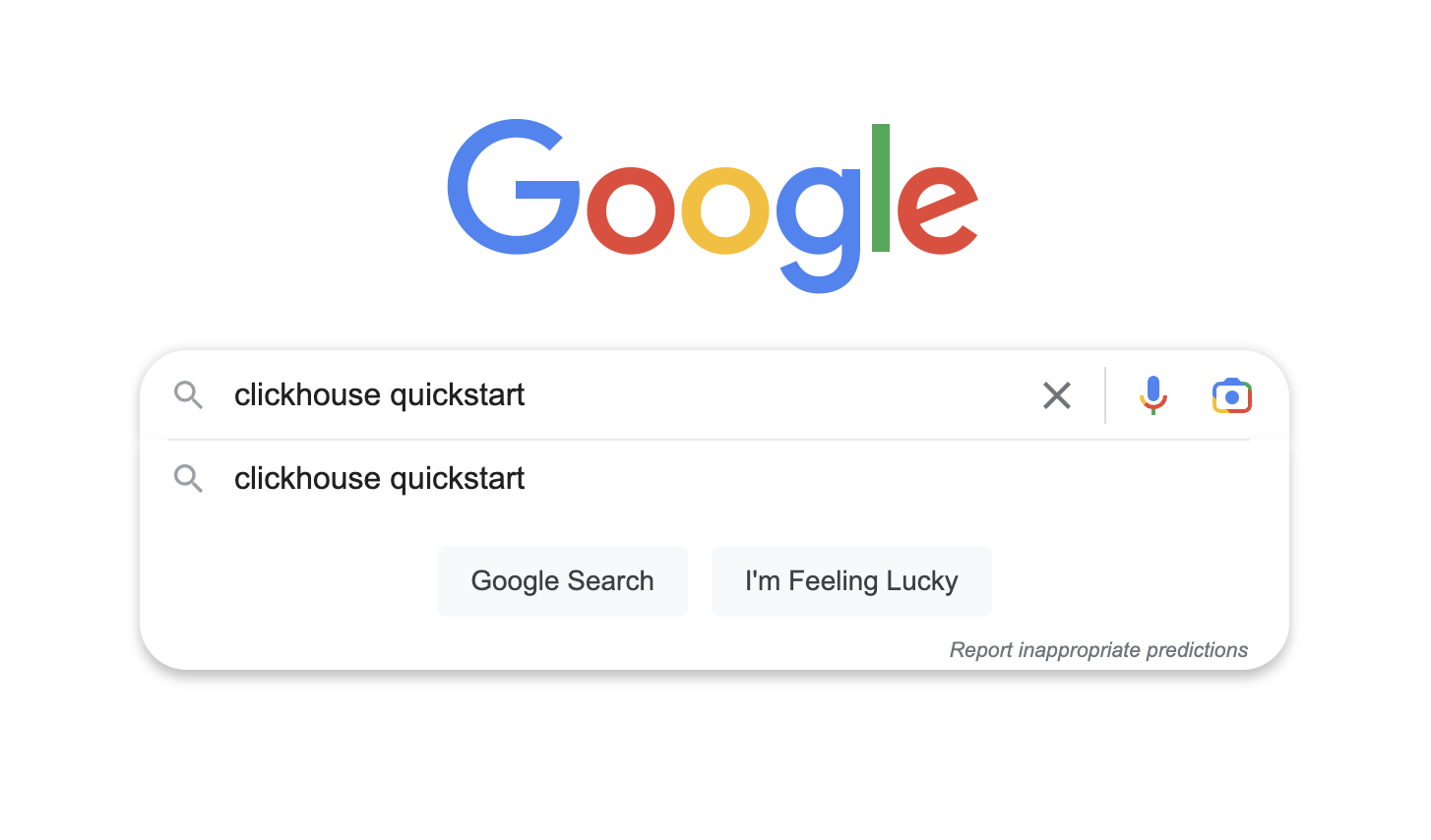
👍 First hit is https://clickhouse.com/docs/en/quick-start/ and it looks exactly like what I'm looking for.
Note: This may or may not be representative of most developers, but I never watch videos, and definitely not for a quickstart because a product's quickstart should be straightforward enough that a video is not necessary. It is nice that the video is available for the few who want it, but I ignore it.
😕 First thing I try is clicking Get Started, because it looks like a clickable button. However, this is not clickable, it's just how the page heading is formatted.
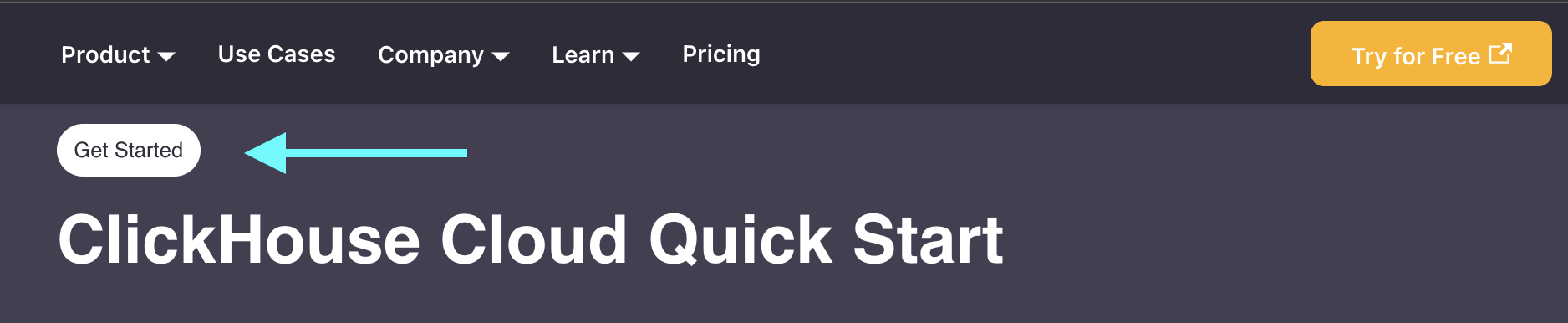
I scroll past the video and dive into the Step 1 and click on sign-up page.
😕 The quickstart also states that the following will need to be done after signing up, but I didn't have to do this.
- Verify your email address (by clicking the link in the email you receive)
- Login using the username and password you just created
💡 Assuming the discrepancy is that the instructions are written for developers who sign up without Google SSO, these instructions may need to be updated.
Instead I click on the Try for Free link and get to the ClickHouse Cloud signup page.
❤️ For developers, it's excellent to see upfront that there is free 30-day trial with some dollar allocation towards free usage.
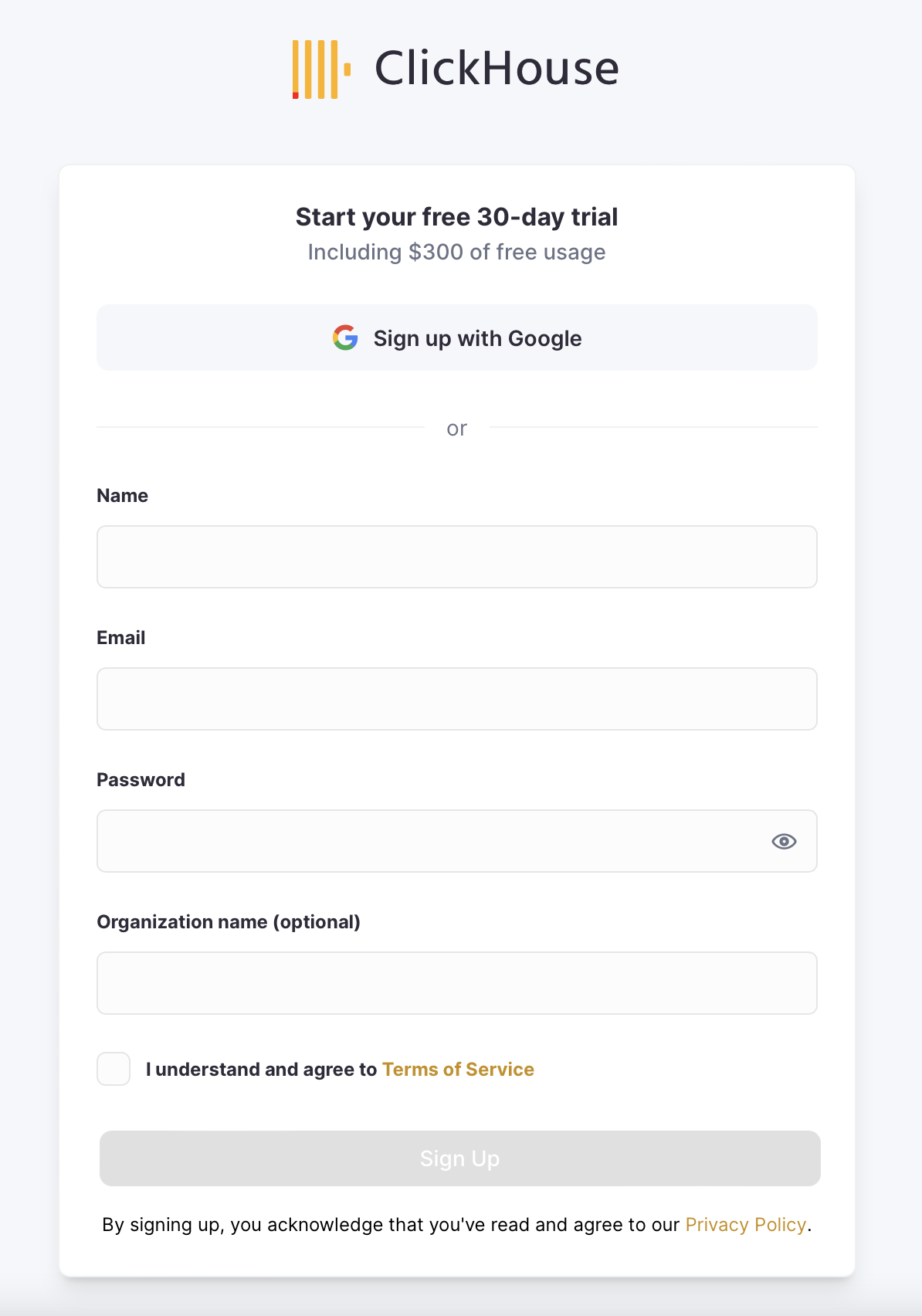
❌ And now the Sign up with Google button is not clickable, and I know that's supposed to be a button! Refreshing the page doesn't help.
After a few seconds, I realize that the button is not clickable until the checkbox I understand and agree to Terms of Service at the bottom of the form is checked.
Which is especially easy to miss because of the form's or placement.
💡 It would be helpful to relocate the checkbox to draw more attention to it, or move it to a different part of the signup workflow.
✅ Finally signed up with my Google identity!
👍 After signup, the next few pages are excellent as they guide the developer to create their first ClickHouse database. There are three simple decisions to make: cloud provider, region, and service name.
Note that even though I have pulled up the ClickHouse quickstart in one tab, I am not following it directly at the moment.
The next page is about securing incoming connections: it can be permissive, i.e., Anywhere, or restricted like an "allowlist".
For the purpose of getting started, it's easier to have a permissive policy in order to not to deal with additional overhead of figuring out and adding my IP address, so I am tempted to select Anywhere.
But I go back to the documentation to see what it says about it.
Notice your local IP address is already added...
😕 The ClickHouse Cloud page did not say that my local IP address is already added!
But because I assume that my local IP address will be added, I change my mind and decide to select Specific locations instead of Anywhere.
Ah ha! After selecting the Specific locations tile, it now shows my local IP address is added!
💡 On the ClickHouse Cloud page, the explanation shouldn't appear only after it's selected.
Consider adding some small verbiage to the page, otherwise I would have selected Anywhere if I hadn't checked the documentation.
Finally, the ClickHouse database user has been generated. The page shows auto-generated credentials that are supposedly going to be presented to me only once, so I download them to my laptop.
✅ I've got a ClickHouse database!
ClickHouse Quickstart
First I go to View connection string to see how to connect to it, if I were to do so (note: I didn't download the ClickHouse client).
❌ It shows the credentials again, the same credentials I had already downloaded during the signup workflow, which said it was only going to be shown once.
{kind=link}
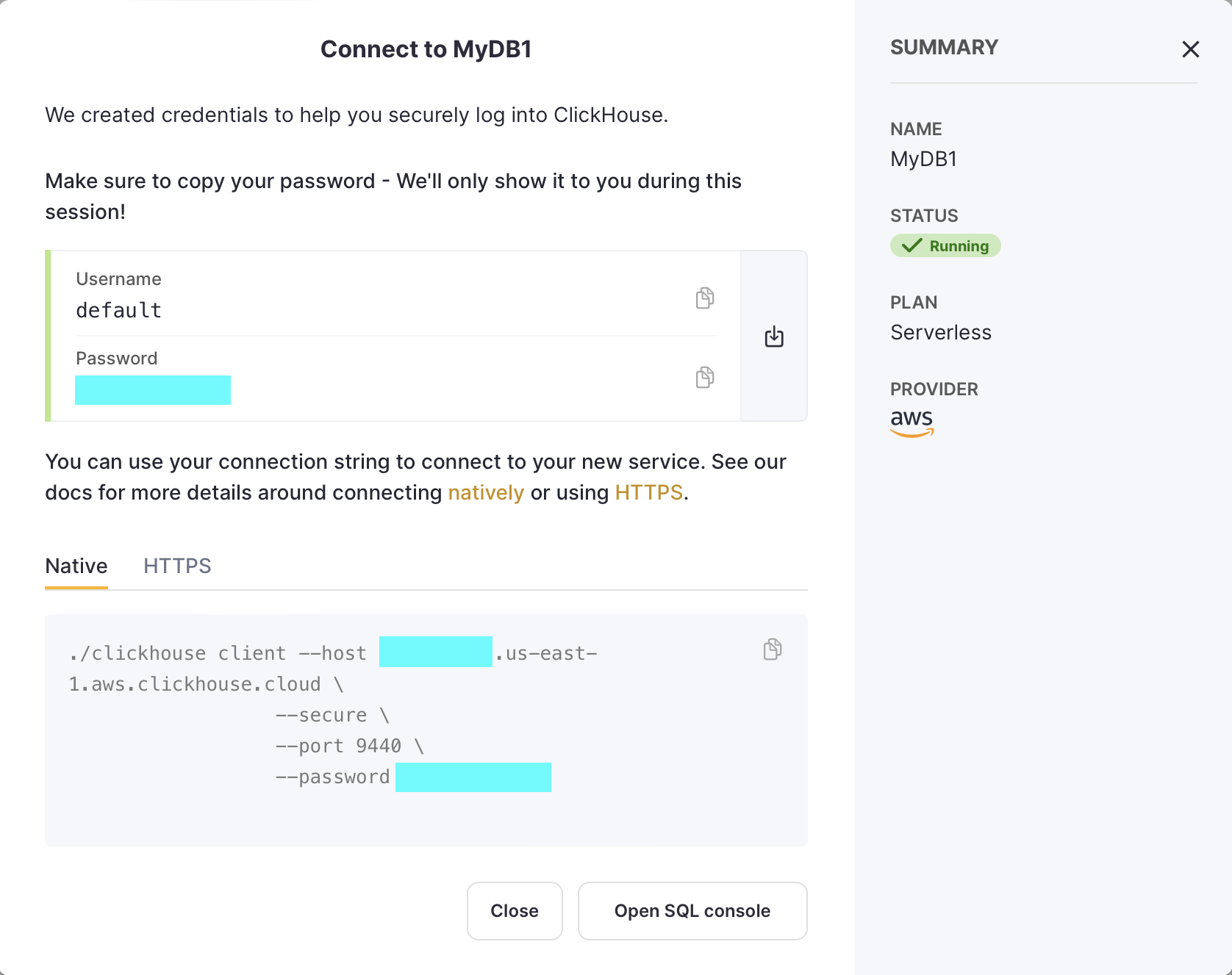
💡 When it comes to security and showing credentials, it has to be consistent. If the product says the credentials will be shown once, then it should be shown once and only once.
I then connect to the database via the SQL console provided in the ClickHouse browser.
❤️ For the getting started experience, a SQL console in the browser—with links on what to do next—is incredibly helpful!
The first tile, Quick Start Tutorial, seems like a good place to start.
😕 However it opens a new browser tab and takes me back to the same ClickHouse quickstart that I already had opened in another tab.
💡 Developers may not expect to be bumped out of ClickHouse Cloud and into the documentation. An in-browser step-by-step guide may be more instructive.
Rescanning the quickstart, the documentation says Enter a simple query to verify that your connection is working.
😕 From the ClickHouse Cloud dashboard, there's no obvious place to enter the query.
I eventually notice Click on a table or create a new query to get started.
There are no tables shown, but create a new query seems like a good link, and it opens exactly the SQL console that I was looking for.
💡 In the documentation, explicitly state how to get to the SQL console. Also perhaps in the ClickHouse Cloud page itself, it could be a bit more apparent.
As the quickstart suggests, I enter SHOW databases.
💡 Minor enhancements to consider in the documentation since it may not be apparent to new users:
- Tell users to click
Runafter entering the query. - In addition to saying that 4 databases are in the list, show the output.
Switching back and forth between the quickstart documentation and the SQL console...the quickstart suggests new queries to run in the SQL console.
😕 It is not immediately clear whether the new queries should be:
- Inline replacement, i.e., replace
SHOW databaseson line 1 - Added on a new line in the same worksheet, i.e., on line 2 and beyond
- Added on a new worksheet
❌ I opt for #2, adding it a new line in the same worksheet, but that results in an error.
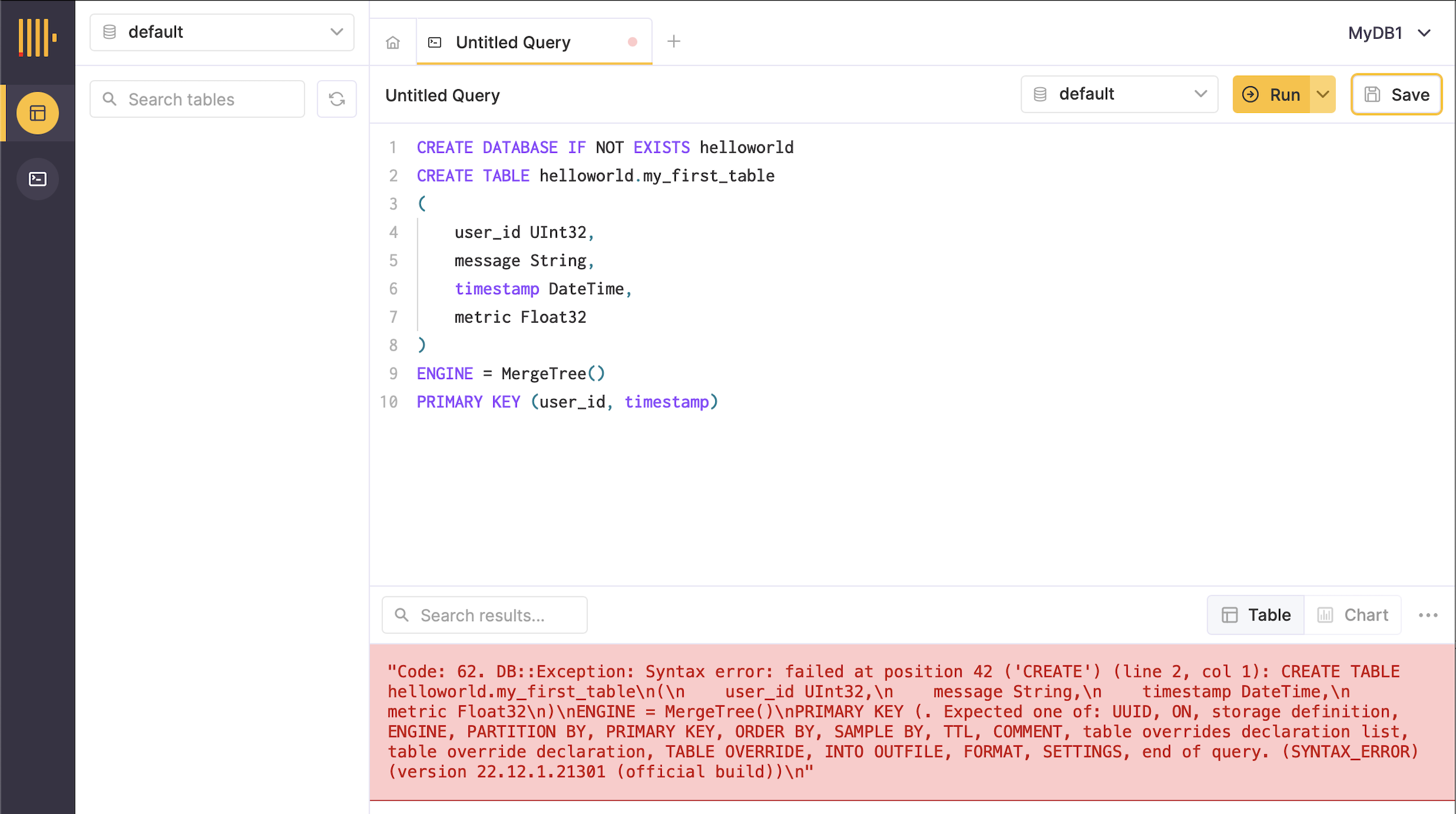
From prior experience with SQL, I figure out to add a ; at the end of the first line (see below) and then it works!
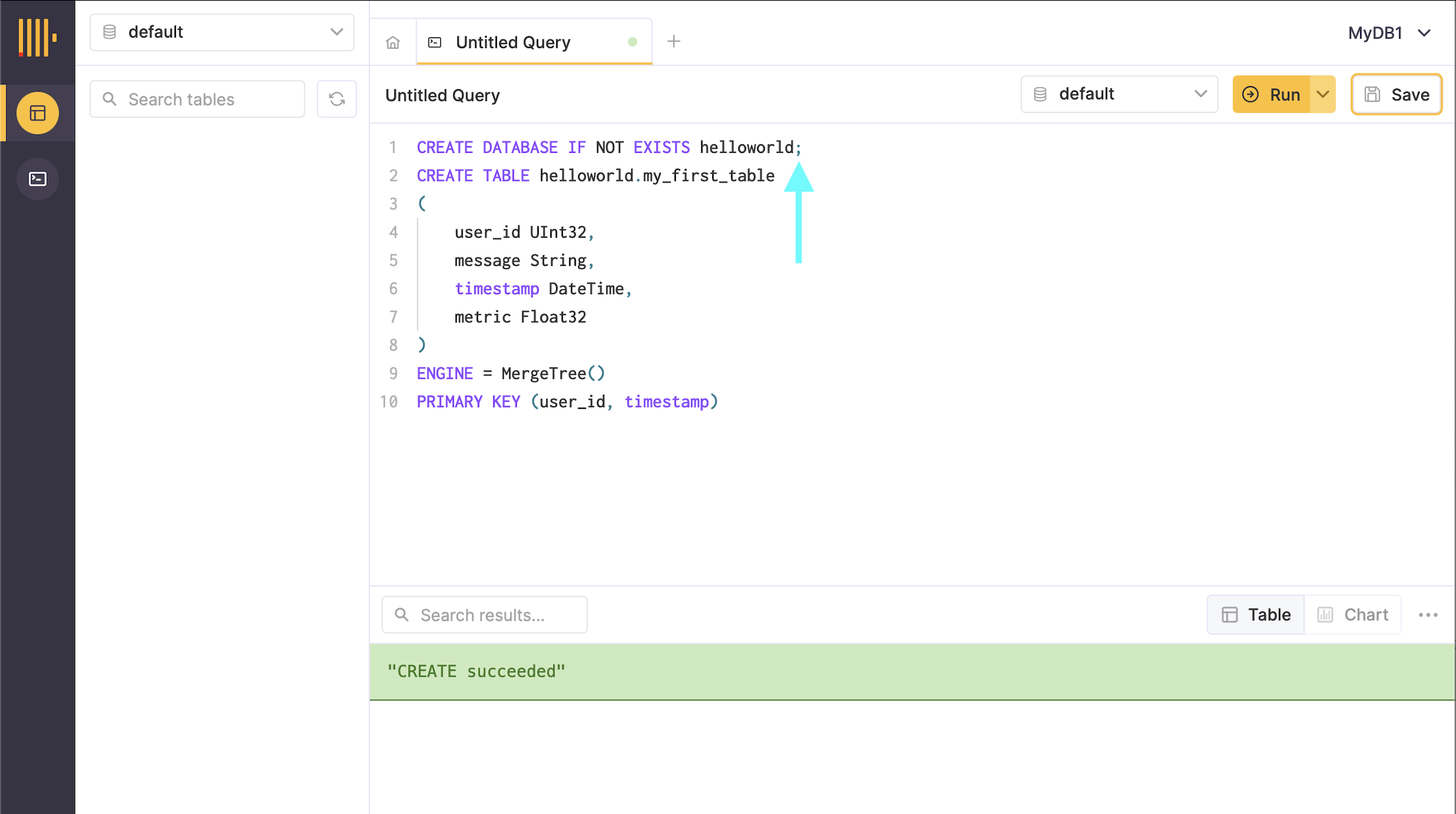
💡 For consideration, enhance the docs to add the semi-colon and mention running the subsequent commands on new lines, but maybe there is a product enhancement as well to improve the error message.
😕 The quickstart documentation calls out behavior of primary keys, which is helpful if it differs from a developer's expectation about how they work, but this is too much detail in a quickstart and it stalls progress on the quickstart.
Developers may not want to learn all these new terms like index granularity, primary key index file, sparse index, stripe, interaction between PRIMARY KEY and ORDER BY clause, etc. at this point.
💡 For consideration, just mention that primary keys have some interesting behavior and then link out to separate documentation page for more details.
👎 From the documentation, You can use the familiar INSERT INTO TABLE command with ClickHouse. Please never assume anything is "familiar", or for that matter, "obvious" or "easy". Developers who are brand new to SQL may have no knowledge of INSERT INTO TABLE.
In the existing SQL console with the previous two queries (SHOW databases and CREATE TABLE...), I add on the new query for the INSERT INTO.
❌ The INSERT INTO query fails due to an error: Table helloworld.my_first_table already exists., which is a rerun of the CREATE TABLE command I ran from the quickstart.
💡 Add IF NOT EXISTS to the commands so they don't fail when they are rerun, e.g. change
CREATE TABLE helloworld.my_first_table...
to
CREATE TABLE IF NOT EXISTS helloworld.my_first_table
✅ After completing Step 4: Insert Data, I feel I've gotten my bearings in ClickHouse Cloud.
I don't feel compelled to complete the remaining steps Step 5: Using the ClickHouse Client and Step 6: Insert a CSV file, and am ready to try out the Kafka connector.
This quickstart accomplishes its goal of getting a developer set up in ClickHouse Cloud, but it doesn't begin to demonstrate how ClickHouse is different than other SaaS database offerings. It's not until the What's Next? section at the end of the page, that it gets to the ClickHouse value proposition, like the New York taxi tutorial.
👎 Lists of content in a "What's Next" section often get ignored by readers, which means developers may never get to the interesting tutorial.
💡 To address this, for consideration, trim the remaining steps of the quickstart to avoid dropoff and/or extend the workflow to more explicitly steer developers to the additional tutorials that demonstrate the value of ClickHouse.
Kafka connector
To start, the documentation for ClickHouse Kafka Connect Sink mentions both Apache Kafka and Confluent Platform, which packages Apache Kafka, but some developers may be confused about their respective versioning schemes:
- Apache Kafka version, which is stated should be version 3.0 or later
- Confluent Platform, which is on a different versioning scheme, and it should be version 7.0 or later to get the bundled Kafka version 3.0 or later
💡 It would be helpful to clarify the versioning, perhaps link out to the Confluent Platform and Apache Kafka Compatibility
Following the instructions, I download the latest ClickHouse Kafka connector clickhouse-kafka-connect-0.0.4.zip.
The next step is Extract the ZIP file content and copy it to the desired location, which is a bit vague but it may vary depending on how Kafka Connect is deployed.
✅ In my environment, I am running Confluent Platform locally and move the JAR file to $CONFLUENT_HOME/share/java/kafka/.
Upon starting Confluent Platform, the command confluent local services connect plugin list shows that the ClickHouse plugin is available.
Available Connect Plugins:
[
{
"class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
"type": "sink",
"version": "0.0.1"
},
.....
]
😕 Is version 0.0.1 correct, considering the GitHub connector JAR is from the release 0.0.4?
💡 How Kafka Connect is deployed in a user's environment will vary (Apache Kafka distribution, Confluent Platform tarball, Docker, Kubernetes, etc) but it would be helpful to at least show a green path. So instead of leaving it up to the user to figure out versioning, copy it to the desired location, verification commands, etc, provide at least one way that works.
To test this connector, there needs to be data in the Kafka cluster that will be written to the ClickHouse database. For this purpose, I also install the Datagen Source Connector.
confluent-hub install --no-prompt confluentinc/kafka-connect-datagen:latest
✅ At this point, Confluent Platform is running with the right plugins for the Datagen Source Connector and the ClickHouse Sink Connector.
Next step, a datagen connector is deployed to write records to a Kafka topic called users:
Current configuration of DatagenConnectorConnector_0:
{
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"quickstart": "users",
"name": "DatagenConnectorConnector_0",
"kafka.topic": "users"
}
Then I attempt to deploy the Clickhouse connector by running the command
confluent local services connect connector \
config clickhouse-sink --config clickhouse-sink.json
Where the connector configuration file clickhouse-sink.json is:
{
"name": "clickhouse-sink",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
"topics": "users",
"hostname": "<redacted>",
"port": "8443",
"database": "default",
"username": "default",
"password": "<redacted>",
"ssl": "true",
"tasks.max": "1"
}
}
❌ The connector task fails, and digging through the connect logs, it shows the error Did not find any tables in destination Please create before running.
The ClickHouse connector documentation does in fact mention that the table should exist, but it's in a section called Target Tables far below how far I read (pssst, developers don't read an entire documentation page before trying things out).
💡 A possible product enhancement is for the connector itself to create the table if it doesn't exist, and this precedent already exists for some other Kafka connectors. Other than that, the documentation should state at the top that the table needs to be pre-created in ClickHouse, otherwise it is a hard failure.
The Datagen connector is configured to create records from the users schema. From the quickstart example, I venture a guess as to what the query is to create that table.
CREATE TABLE IF NOT EXISTS users
(
registertime DateTime,
userid String,
regionid String,
gender String
)
ENGINE = MergeTree()
PRIMARY KEY (userid, registertime);
❌ Redeploying the connector fails again, with the error Table column name [registertime] type [NONE] is not matching data column type [INT64].
In the second attempt, I change DateTime to Int64, which matches the long type in the datagen users schema:
registertime Int64,
✅ Now the connector runs and copies all the data from the Kafka topic users to the table in the ClickHouse database!
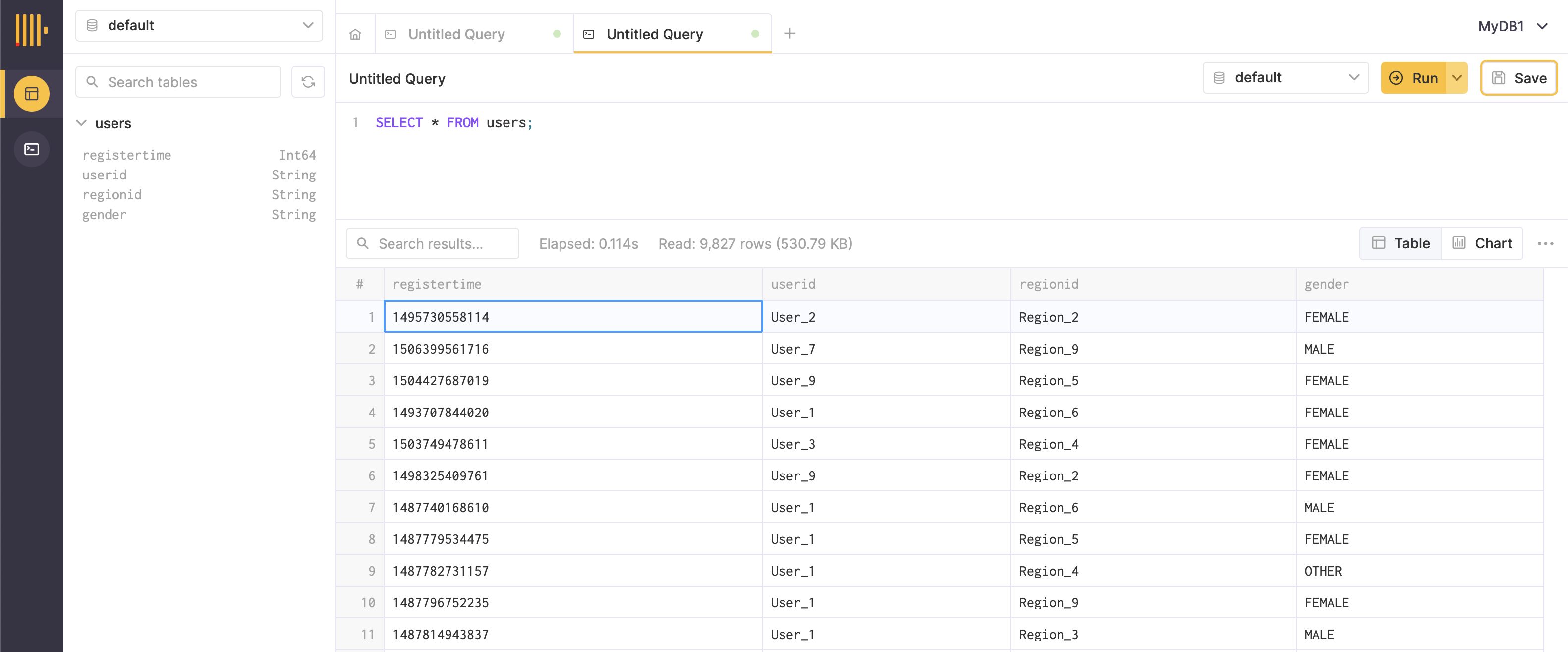
From the SQL console in ClickHouse Cloud, a SELECT * FROM users; shows all the rows.

🎉 Successfully got the Kafka --> ClickHouse pipeline working!